Книги
Статистика и котики
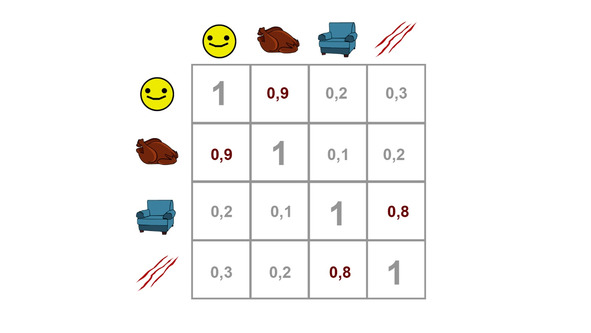
Во-вторых, переменные, которые коррелируют между собой, заменяются факторами. Чтобы понять, как это происходит, обратимся к рисунку.
На нем уже знакомая нам линейная взаимосвязь, которая описывается регрессионной прямой. Давайте теперь повернем наш рисунок таким образом, чтобы эта прямая лежала по горизонтали, и проведем прямую, перпендикулярную регрессионной.
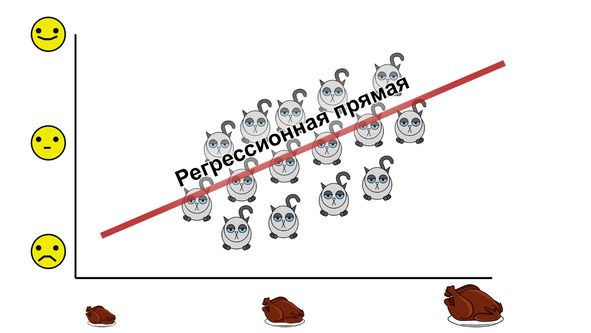
У нас получилась новая система координат. При этом большая часть котиков лежит вдоль оси Х. Эта ось и будет являться фактором, заменяющим как количество поглощаемой пищи, так и котиковое счастье.
В итоге мы получаем вот такую таблицу, которая называется
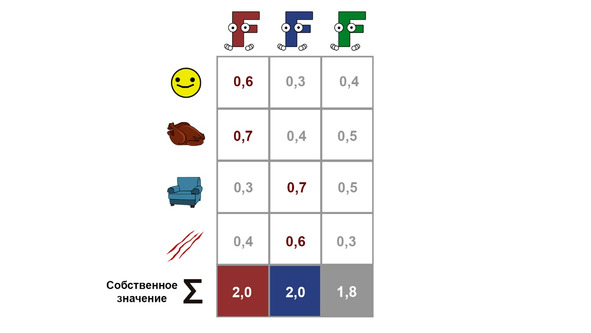
Далее происходит так называемая процедура

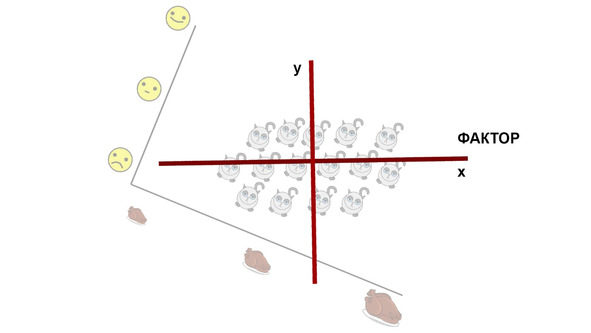
Чтобы прояснить, как работает вращение, также обратимся к рисунку. На нем изображена переменная «Счастье», которая коррелирует с первым и вторым факторами. Координаты «Счастье» — это коэффициенты корреляции между ним и факторами.
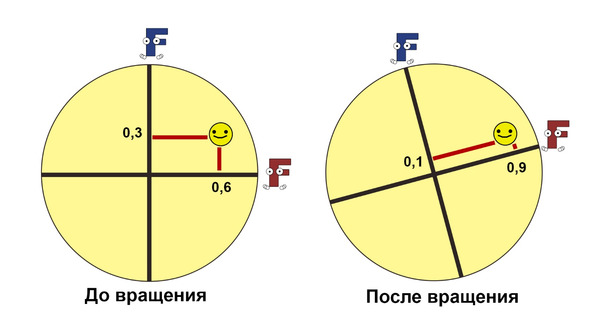
Если мы будем вращать окружность против часовой стрелки, то координаты «Счастья» будут меняться. Соответственно, оно будет больше коррелировать с первым фактором и меньше — со вторым.
Вращение бывает двух видов —
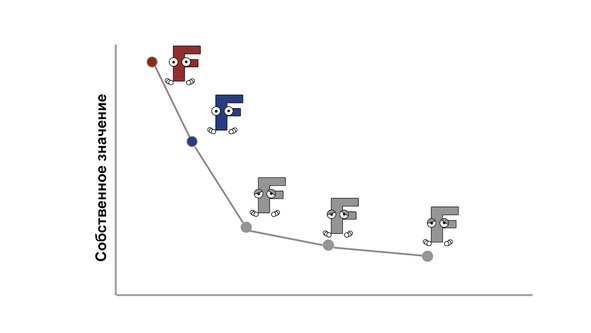
Предпоследняя процедура — это отсеивание лишних факторов, которые слабо связаны с первоначальными переменными. Для этого существует два способа. Первый (называемый
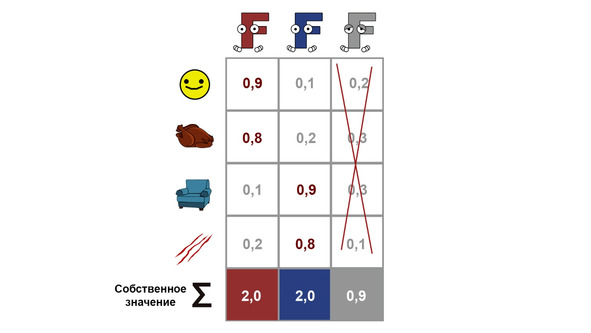
Второй способ называется
И наконец последний шаг — это придумать название получившимся факторам. Этот шаг является довольно нетривиальным — подчас он вызывает наибольшие затруднения. Но если вы успешно преодолеете его, то у вас на руках может оказаться довольно неплохая структурная модель котикового характера. В нашем случае первый фактор будет называться «жизнерадостностью», а второй — «царапучестью».
НЕМАЛОВАЖНО ЗНАТЬ!
Применение факторного анализа
Изначально факторный анализ был разработан психологами для изучения способностей и личностных качеств. Однако со временем область применения данного метода существенно расширилась.
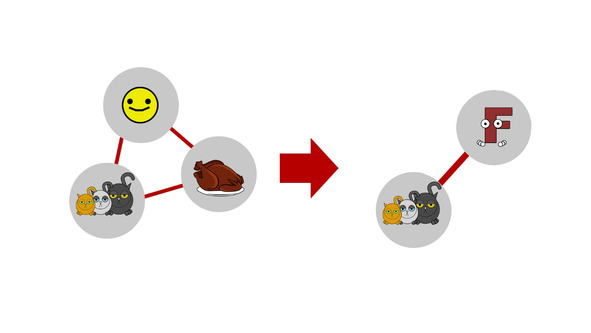
Первая большая проблема, которую позволяет решить факторный анализ, это сокращение количества переменных. Как правило, серьезные исследования подразумевают сбор большого количества данных. Настолько большого, что в них бывает очень трудно разобраться. В этом случае факторный анализ позволяет уменьшить их количество за счет замены изначальных переменных факторами.

Вторая задача, требующая применения факторного анализа, это устранение мультиколлинеарности из регрессионных моделей. Напомним, что эта проблема заключается в том, что если две или более переменные взаимосвязаны между собой, результаты регрессионного анализа будут крайне ненадежными. Поэтому такие переменные требуется удалить из анализа. И один из путей — это замена таких переменных факторами.
Заключение
Ну вот и все. Ну, может, конечно, и не все: статистика все-таки гораздо богаче, и многое осталось за бортом. Но пока все. Потому что если объяснять совсем все, то пропадает интерес. А интерес — движущая сила в познании любого предмета. Да и потом, совсем все не объяснишь.
А так, мы рассмотрели самые базовые методы, которыми пользуются статистики для анализа данных. Мы прошлись по описательной статистике, рассмотрели меры различий и меры связи, познакомились с регрессионным и дискриминантным анализами, а также разобрались, как работают методы кластеризации и для чего используется факторный анализ. В общем, немало.
Надеюсь, что статистика стала вам ближе. Надеюсь, что страх и недоверие, если они и были, то прошли. Надеюсь, что вы заметили ту внутреннюю красоту, которая присуща этой дисциплине.