Книги
Информационное обеспечение туризма: креативное управление
Задача обеспечения требуемого уровня достоверности вызывает необходимость применения процедур контроля на всех основных этапах технологического процесса обработки информации. Особому контролю подвергается достоверность выходных (производных) документов, перед выдачей их абоненту. Корректировка ошибок обусловливает необходимость привлечения дополнительных довольно значительных трудовых, материальных, финансовых и временных ресурсов. Иногда искажения в документах вызывает необходимость повторной обработки документов на ЭВМ. Для устранения подобных случаев усиливается внимание по обнаружению и исправлению ошибок на предмашинных этапах обработки. В связи с этим, особую значимость приобретает программный контроль достоверности на этапе ввода данных в ЭВМ.
Достоверность и полнота информации в ИСТ обеспечивается различным комплексом методов защиты: аппаратными, программными, организационными, комбинированными и др. По уровню применения технических средств методы контроля достоверности информации можно разделить на следующие основные категории: ручной, механический, автоматизированный и автоматический. Ручной или визуальный способ заключается в проверке правильности данных без применения каких-либо технических средств. При механическом способе применяются вспомогательные технические устройства, например, калькуляторы для подсчёта контрольных сумм для пачки документов. Автоматизированный метод контроля состоит в диагностике правильности данных посредством соответствующих программных модулей пакетов прикладных программ (ППП). Автоматический метод состоит в программном выявлении ошибочного данного, определения его истинного значения и замены ошибочного значения на истинное значение в памяти ЭВМ [21, 26]. Степень применения методов контроля данных зависит от класса и масштаба ИСТ.
В значительной части систем организационного управления ввод информации в ЭВМ производится в форме документов [14]. С целью реализации контроля достоверности входной информации разрабатываются специальные прикладные программы. Эти диагностические программы ориентированы на контроль формальных и содержательных параметров входных первичных документов. При обнаружении ошибок они выдают сообщения оператору об адресе и модификации ошибки. Анализ работ по контролю достоверности данных показывает, что имеющиеся методы и программы контроля достоверности и полноты информации направлены, в основном, на обнаружение ошибок, их идентификацию. Исправление ошибок, восстановление достоверности данных выполняется только при непосредственном участии человека.
С целью определения основных требований к методам и средствам повышения уровня достоверности обратимся к технологии обработки данных ИСТ. Почти каждый этап обработки сопровождается выполнением операций контроля данных, в которых значительный объём приходится на контроль достоверности и полноты сведений в обрабатываемых документах. Особо тщательно должна проверяться производная документация перед выдачей её абонентам. Неадекватность сведений в документации влечёт соответственно снижение эффективности принимаемых решений. Иногда это обусловливает повторную обработку пакета первичных документов, что увеличивает стоимость обработки информации, снижает уровень своевременности, ухудшает свойства результатной информации.
Проведём рассмотрение методов контроля в части реализации функций обеспечения достоверности и полноты информации (таблица 3.14). По выполняемым функциям эти методы контроля можно разделить на лексические, синтаксические, логические и арифметические. Сформулируем здесь некоторые методы контроля.
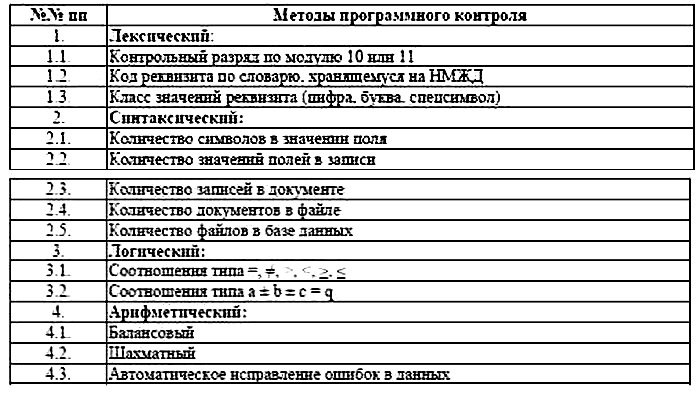
=,
Распространённым методом контроля является
Следует отметить, что реализация методов контроля, как правило, влечёт за собой необходимость введения в процессы обработки избыточности информационного, программного, технологического и организационного характера. Так, например, балансовой контроль, как разновидность арифметического контроля, предусматривает наличие в документе контрольных сумм, которые по существу являются избыточной информацией. Кроме того, программный модуль контроля достоверности информации в сущности является избыточным также в структуре программного обеспечения ИСТ. В технологии обработки данных предусматриваются процедуры контроля информации являющиеся также избыточными. Технологическая избыточность обусловливает организационную избыточность, например, необходимо проводить инструктаж персонала, отвечающего за процедуры контроля достоверности информации.
Методы контроля по характеру возникновения ошибок можно подразделить на ошибки человеческого и технического факторов. Дефекты информации, вызываемые техническими средствами обработки, нейтрализуются на компьютерном уровне специальными методами и средствами, например, функциональными блоками ЭВМ, устройств ввода-вывода, системы передачи данных и др. Ошибки человеческого фактора исправляются гораздо сложнее. Каким образом происходит обнаружение ошибок и их исправление? В процедурном отношении последовательность программного обнаружения ошибок и последующего их исправления можно отобразить схемой корректировки ошибок в технологии обработки данных ИСТ (рис. 3.4).
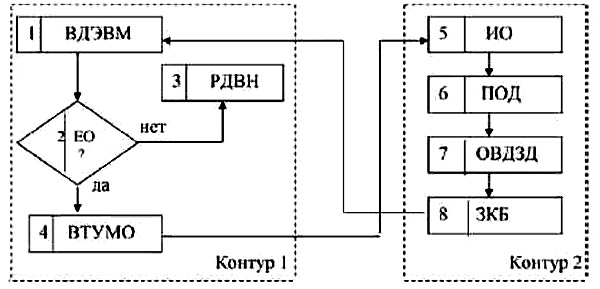
Схема состоит из контура 1 – этапы, выполняемые посредством ЭВМ, и контура 2 – этапы, выполняемые вручную. На этапе 1 происходит ввод данных в ЭВМ (ВДЭВМ). На этапе 2 проводится анализ входных документов посредством программ контроля правильности входных данных (ЕО?). При отсутствии ошибки документ на этапе 3 размещается на внешнем накопителе ЭВМ (РДВН). Если ошибка обнаружена, то на этапе 4 сведения о ней выводятся на терминальное устройство (ВТУМО), например, дисплей или принтер. На этапе 5 происходит идентификация ошибки (ИО). Затем на этапе 6 выполняется обращение к массиву первичных документов и поиск соответствующего ошибочного документа (ПОД). На этапе 7 происходит определение и (или) вычисление достоверного значения показателя документа (ОВДЗД). Ошибки в документах могут иметь самые различные модификации. Дефектом может быть отсутствие (пропуск) значения показателя в документо-строке (документо-графе), искажение значения показателя документа и др. Искажение значения показателя (данного в записи) может быть допущено за счёт недостающего или лишнего количества символов в значении показателя, искажения какого-либо символа, внедрения в цифровое значение алфавитного символа или наоборот, транспозиции («наползания») символов одного значения на другое и др. На этапе 8 происходит заполнение оператором «Корректировочного бланка» (3КБ) [29] достоверными значениями показателей с указанием режимов корректировки – «замена», «удаление», «вставка» и др. Далее данные «Корректировочного бланка» вводятся в ЭВМ и таким образом ошибки исправляются. Операции контура 1 по сравнению с операциями контура 2 составляют значительную долю трудозатрат и времени на этапе ввода и контроля документов в ЭВМ.
Наибольшей степенью реализации являются синтаксические методы, контролирующие в основном параметры структуры входных документов. Однако семантические свойства в методах контроля учитываются недостаточно. Необходимость обеспечения контроля как можно большего набора параметров входных документов вызывает увеличение числа соответствующих программных модулей. Подобная программная избыточность в общем случае отрицательно сказывается на значениях обобщённых показателей ИСТ. Исходя из принципов контроля информационной системы, максимального перевода функций контроля от человека к ЭВМ, необходим способ, который не только бы обнаруживал ошибки, но и программно вычислял достоверные значения показателей и заменял бы ими соответствующие ошибочные значения. Подобный метод мог бы в значительной мере устранить необходимость дополнительной трудоёмкости при исправлении дефектов достоверности и полноты (рис. 2.4, блоки 5–8), минимизировать объём трудовых, материальных и финансовых ресурсов.
Такой алгоритм и соответствующая программа должны обеспечить автоматическое исправление обнаруженных ошибок в каждом первичном документе с выводом на принтер или видеотерминал при необходимости сообщений оператору адресов и модификаций исправляемых ошибок.
Таким образом, алгоритм и программа автоматического обнаружения ошибок и восстановления достоверности значений показателей документов должны удовлетворять следующим требованиям:
• повышение уровня достоверности, полноты и своевременности информации;
• снижение объёмов временных, трудовых, материальных и финансовых ресурсов, используемых в технологии обработки данных;
• адаптация к сравнительно широкому классу обрабатываемых форматов табличных документов;
• дружественный интерфейс;
• возможность применения в других технологиях обработки данных;
• реализация максимального состава функций лексического, синтаксического, логического и арифметического контроля при условии сравнительно минимального физического объёма программного модуля.