Книги
Цифры врут. Как не дать статистике обмануть себя
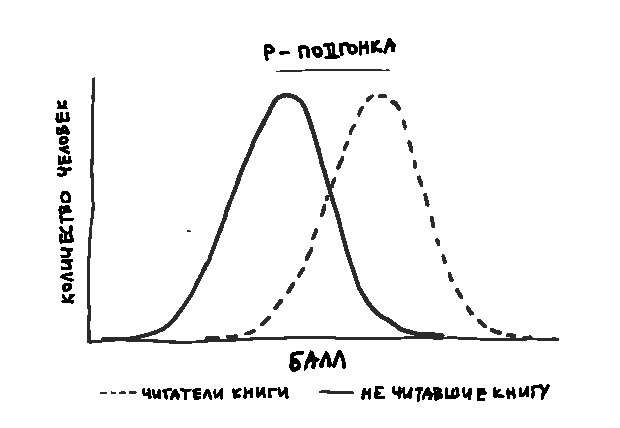
Если же верна альтернативная гипотеза, то средний балл читателей будет выше среднего балла другой группы и кривая распределения для этой группы сместится вправо.
Но даже если верна нулевая гипотеза и книга не оказывает никакого эффекта; если – внезапно – окажется, что обе группы одинаково хорошо разбираются в статистике, все равно останется одна проблема – вам не избежать случайных вариаций. У кого-то будет просто неудачный день. Вспомните фильм «Осторожно! Двери закрываются» – Гвинет Пэлтроу в одной вселенной пропускает свой поезд, опаздывает на наш тест, расстраивается и сдает его плохо; а в другой – приходит вовремя, блестяще отвечает на вопросы и влюбляется в Джона Ханну. Пунктуальность и душевное равновесие, вероятно, не сделают из девушки эксперта по статистике, однако благоприятно отразятся на результатах теста. Есть некоторая (пусть и небольшая) доля случайности в том, насколько хорошо каждый участник выполнит задания.[12]
Если несколько не читавших книгу выполнят тест очень плохо, а несколько прочитавших – очень хорошо, это может заметно изменить среднее значение – покажется, что читатели в общем проходят тест намного лучше.
Итак, представим, что по какой-то причине ваши результаты говорят, что читатели лучше справляются с тестом. Теперь важно узнать, насколько вероятно получить такие (или еще более экстремальные) результаты, если верна ваша нулевая гипотеза – чтение книги не влияет, а все вариации случайны. Это и называется проверкой достоверности.
Нет конкретного значения, при котором абсолютно ясно, что нулевая гипотеза неверна: теоретически даже самые сильные различия могут оказаться случайными. Но чем больше разница, тем меньше шансов, что это случайно. Ученые измеряют шансы случайного совпадения с помощью вероятности, или
Чем менее правдоподобна случайность какого-нибудь события, тем меньше
Во многих науках принято считать, что если
Предположим, что при тестировании средний балл у людей, прочитавших книгу, действительно оказался выше. Если
Статистическая значимость сбивает с толку даже ученых. Исследование 2002 года показывает, что 100 % студентов-психологов и, хуже того, 90 % их преподавателей неправильно трактуют этот термин. В другом исследовании выяснилось, что в 25 из 28 рассмотренных учебников по психологии есть хотя бы одна ошибка в данном определении.
Давайте же разберемся с некоторыми возможными заблуждениями. Во-первых, важно помнить, что статистическая значимость – понятие условное. Нет ничего магического в числе 0,05. Вы можете взять за основу другое: меньшее, тем самым объявляя недостоверными большее число результатов (отнеся их к категории случайных), или большее, расширяя границы статистически значимых данных. Чем выше планка, тем выше риск ложноположительных результатов, чем ниже – тем выше риск ложноотрицательных. Ужесточив критерий, мы можем подумать, что чтение книги никак не сказывается, хотя на самом деле это не так. Ну и, конечно, наоборот.
Во-вторых, статистически значимый результат не обязательно значим в обыденном смысле. Например, если в группе тех, кто книгу не читал, средний балл – 65, а в другой – 68, то результат вполне может считаться статистически значимым, но для вас он вряд ли важен. Статистическая значимость какого-то результата характеризует вероятность его случайного получения, а не его важность.
И в-третьих:
Проблема же в том, что хотя выбор в качестве границы статистической значимости числа 0,05 совершенно условен, ученые и – что еще важнее – редакции научных журналов принимают ее за точку отсечения. Если для ваших результатов
Вернемся же к нашему эксперименту. Мы хотим показать, что эта книга помогает лучше разбираться в статистике и достойна попасть в список бестселлеров
Наверное, просто не повезло, думаем мы. И повторяем эксперимент – достигаем 0,11. И еще, и еще, и еще раз, пока наконец не выходит 0,04. Потрясающе! Мы докладываем о результатах и дальше припеваючи живем на роялти с продажи книги. Только это почти наверняка ложноположительный результат. Если провести эксперимент 20 раз, вполне можно ожидать один случайный результат.
Есть и другие способы достичь желаемого. Мы можем по-разному тасовать данные. Например, не только считать баллы, но и измерять, насколько быстро люди проходят тест, или оценивать красоту почерка. Пусть читатели книги не получают более высокие баллы, но вдруг они быстрее справляются с тестом? Или у них улучшился почерк? А можно отбросить самые крайние результаты, назвав их выбросами. Если ввести достаточно параметров и по-разному сочетать их или внести в данные необходимые и кажущиеся разумными поправки, то по чистой случайности рано или поздно наверняка найдется что-то подходящее.
Теперь вернемся к мужчинам, пытающимся покорить женщин хорошим аппетитом. В конце 2016 года Вансинк, ведущий автор того исследования, опубликовал в своем блоге пост – «Аспирантка, которая никогда не говорила „нет“». Это положило конец его карьере.
Вансинк написал о новой турецкой аспирантке, пришедшей в его лабораторию. Он дал ей данные провалившегося эксперимента, который проводился без внешнего финансирования и имел нулевые результаты. (Это был месячный эксперимент, в ходе которого одним людям продавали входные билеты в итальянский ресторан со шведским столом по цене в два раза выше, чем другим.) Вансинк предложил ей проанализировать данные, потому что, по его мнению, из них можно было что-нибудь извлечь.
По его рекомендации аспирантка сделала это десятками различных способов и – вас это не должно удивить – нашла кучу корреляций. В нашем воображаемом эксперименте с чтением книги мы бы точно так же могли перебирать данные на разные лады, пока бы не обнаружили что-нибудь со значением
Пост в блоге насторожил ученых. Описанная в нем практика называется